In the dynamic world of machine learning, high-performance models depend on substantial and precisely labeled real-world data. Obtaining such datasets is difficult, from gathering large samples to categorizing them precisely. Synthetic data, an emerging alternative, avoids data collection challenges.
Without the hassle of obtaining and annotating big datasets, synthetic data offers an appealing answer using methods that synthesize data with real-world qualities. Synthetic data has many benefits, including cost reduction, improved labeling accuracy, scalability through enormous simulated datasets, and the capacity to model unusual and diverse edge cases.
In an era of abundant computer capacity, the quality of data fed into machine learning models gives a competitive edge. "Getting Started With Synthetic Data" revolutionaryizes using artificial intelligence to generate annotated information, protect data privacy, and solve compliance problems in health, manufacturing, agriculture, and eCommerce.
Starting with synthetic data relevance, applications, and methods. Starting using synthetic data is a smart approach toward optimizing data-driven initiatives in the age of machine learning and AI.
What Is Synthetic Data?
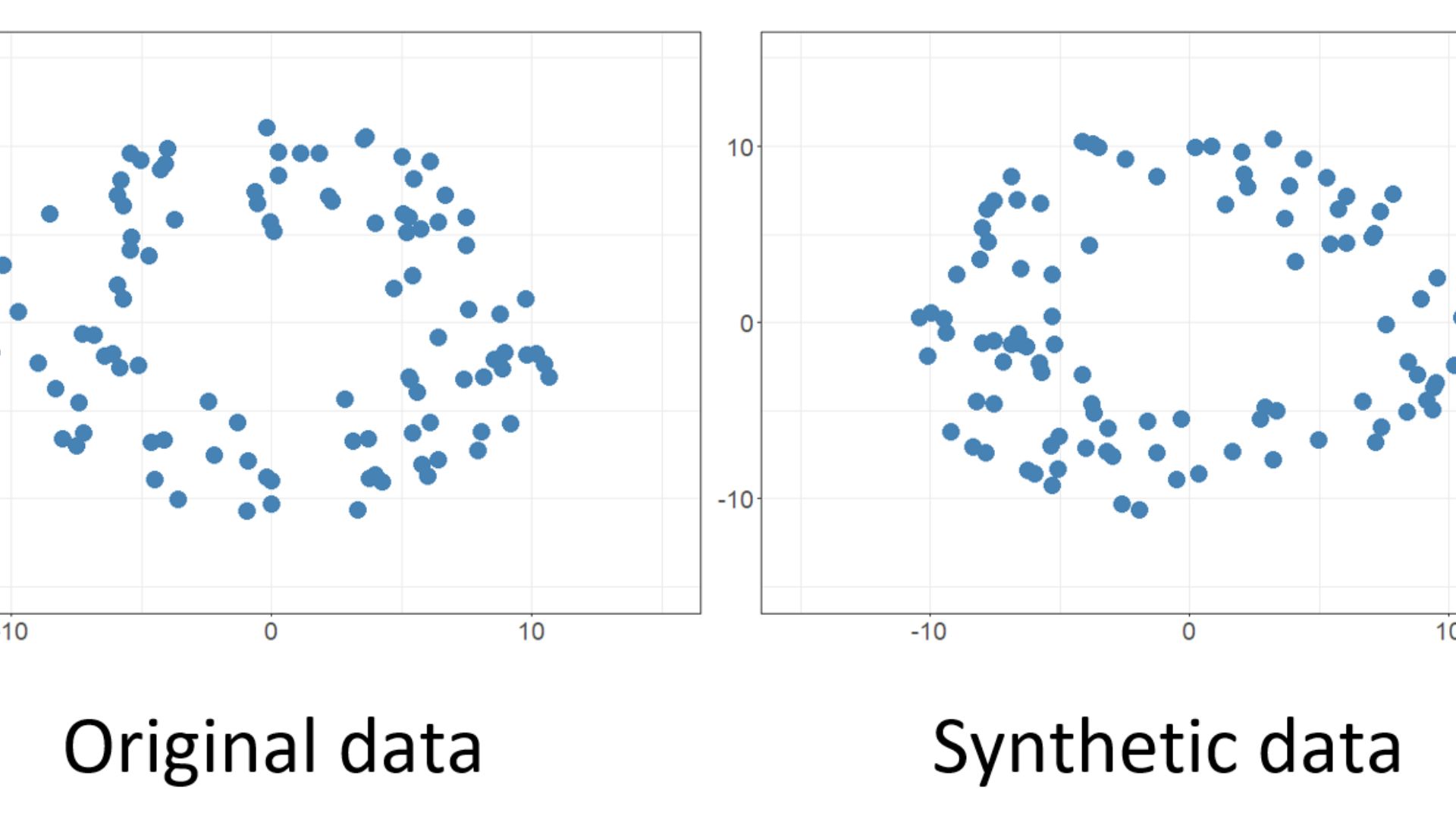
Machine learning algorithms absorb accurate data, train on behavior patterns, and then generate artificial data with the statistical properties of the original dataset. Thus, synthetic data mimics real-world scenarios. This is not the conventional anonymized dataset that may be re-identified. Since synthetic data is artificial, it has fewer weaknesses.
Synthetic data is exempt from data protection rules because it is artificial and privacy-preserving. Analyses and modeling may be done with confidence since this data behaves like accurate data. This unlocks data locked behind compliance barriers, preserves user privacy, and reduces the risk for organizations that use it.
What And When Do We Need To Generate Synthetic Data?
What Is Needed To Generate Synthetic Data
You don't need coding skills to synthesize datasets on MOSTLY AI's synthetic data platform. Free access to the world's best synthetic data production, creating up to 100K rows every day, is even better. No credit card is needed, just a decent sample dataset.
First, create a free synthetic data-generating account with your email. Second, the data sample must be suitable. To generate synthetic data using an AI-powered tool like MOSTLY AI, you must supply a sample dataset from which the AI algorithm can learn. This blog article explains what makes a dataset synthesizable.
When It Is Needed To Generate Synthetic Data
Accurate data is used to create synthetic data for data protection. An AI-powered synthetic data generator may replicate your data larger, smaller, or more realistically. It's not rocket science. Better still, it automates data science.
When choosing a synthetic data generation system, accuracy and privacy are key. All synthetic data generators should be quality-certified, and MOSTLY AI's platform automatically generates privacy and accuracy reports for each set. Most AI synthetic data beats open source.
Knowing how to produce realistic, privacy-safe synthetic data replacements for structured datasets is simple. The no-coding interface of MOSTLY AI's synthetic data platform is simple. Knowledge of synthetic data creation and sample data is enough. Synthetic data creation is explained here.

Importance Of Synthetic Data In Machine Learning
Synthetic data helps train machine learning algorithms. Synthetic data can improve data privacy and availability and create more diverse and complicated datasets.
Machine learning models may become more accurate and robust. Synthetic data is essential for machine learning for these reasons.
Data Privacy
Synthetic data can replace actual data for privacy reasons. Healthcare data with sensitive patient information can be replaced with synthetic data to protect patient privacy and train machine learning algorithms.
Data Scarcity
More data may prevent accurate machine-learning model training. Synthetic data can supplement limited actual data for more accurate models.
Cost-Effectiveness
Training machine learning models using synthetic data is cheaper than gathering and classifying actual data. Banks can train machine learning models to detect fraudulent transactions using generated data. Synthetic data can simulate fraud, improving fraud detection and prevention.
3 Techniques For Generating Synthetic Data
Generating Data According To A Known Distribution
Create a synthetic dataset for simple tabular data without accurate data. Understanding the existing dataset's distribution and the needed data attributes is the first step. A better understanding of data structure means more realistic synthetic data.
Fitting Real Data To A Distribution
For simple tabular data with a real dataset, you can produce synthetic data by finding the best-fit distribution. As shown above, distribution parameters can be used to generate synthetic data points.
The Monte Carlo Method
Multiple random samples and statistical analysis are used in this procedure. It can create realistically random variations on a dataset. Monte Carlo is computationally cheap and has a simple mathematical structure. It is less accurate than other synthetic data-generating approaches.
Neural Network Techniques
Advanced synthetic data generation uses neural networks. These algorithms can synthesize unstructured input like photos and video and handle richer data distributions than decision trees. Three popular neural methods generate synthetic data.
Variational Auto-Encoder (Vae)
An encoded-decoded architecture is an unsupervised technique that learns the distribution of a dataset and generates synthetic data via double transformation. Iterative training reduces the model's reconstruction error.
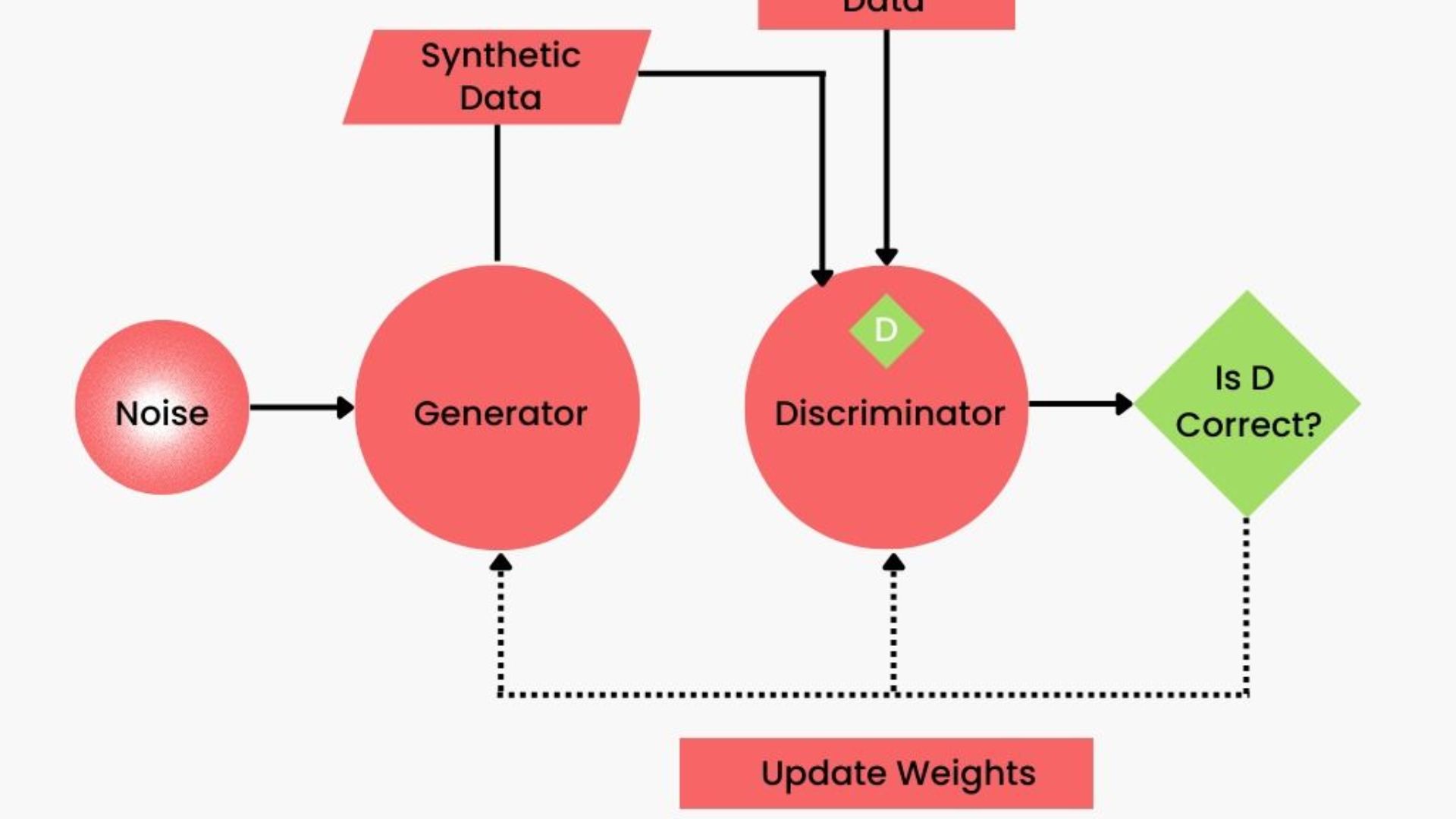
Generative Adversarial Network (Gan)
An algorithm using two neural networks to generate realistic-looking fake data. While one neural network generates bogus data points, the other learns to identify actual samples. Although challenging to train and computationally costly, GAN models can produce realistic synthetic data.
Diffusion Models
Corruption algorithms add Gaussian noise to training data until it becomes pure noise, then train a neural network to gradually denoise until a fresh image is produced. Great training stability and excellent image and audio quality are possible using diffusion models.
Synthetic Data Generation Technologies
Advanced synthetic data-generating technologies are listed below.
Generative Adversarial Network
Generative adversarial network (GAN) models generate and classify data using two neural networks. One synthesizes data from raw data while the other assesses, characterizes, and classifies it. Both networks compete until the evaluating network cannot distinguish synthetic and original data.
Variational Auto-Encoders
VAE algorithms generate new data from original data representations. A twofold transformation using encoder-decoder architecture generates new data after the unsupervised algorithm learns the raw data distribution. The encoder reduces incoming data to a latent form, which the decoder reconstructs. The model recreates smoothly using probabilistic calculations.
Transformer-Based Models
Generative pre-trained transformers or GPT-based models study data structure and distribution using massive original datasets. They are primarily used in NLP generation. On a vast dataset of English text, a transformer-based text model learns the language's structure, syntax, and subtleties. Starting with a seed text (or prompt), the model predicts the following word based on learned probabilities to generate a complete sequence of synthetic data.

Types Of Synthetic Data
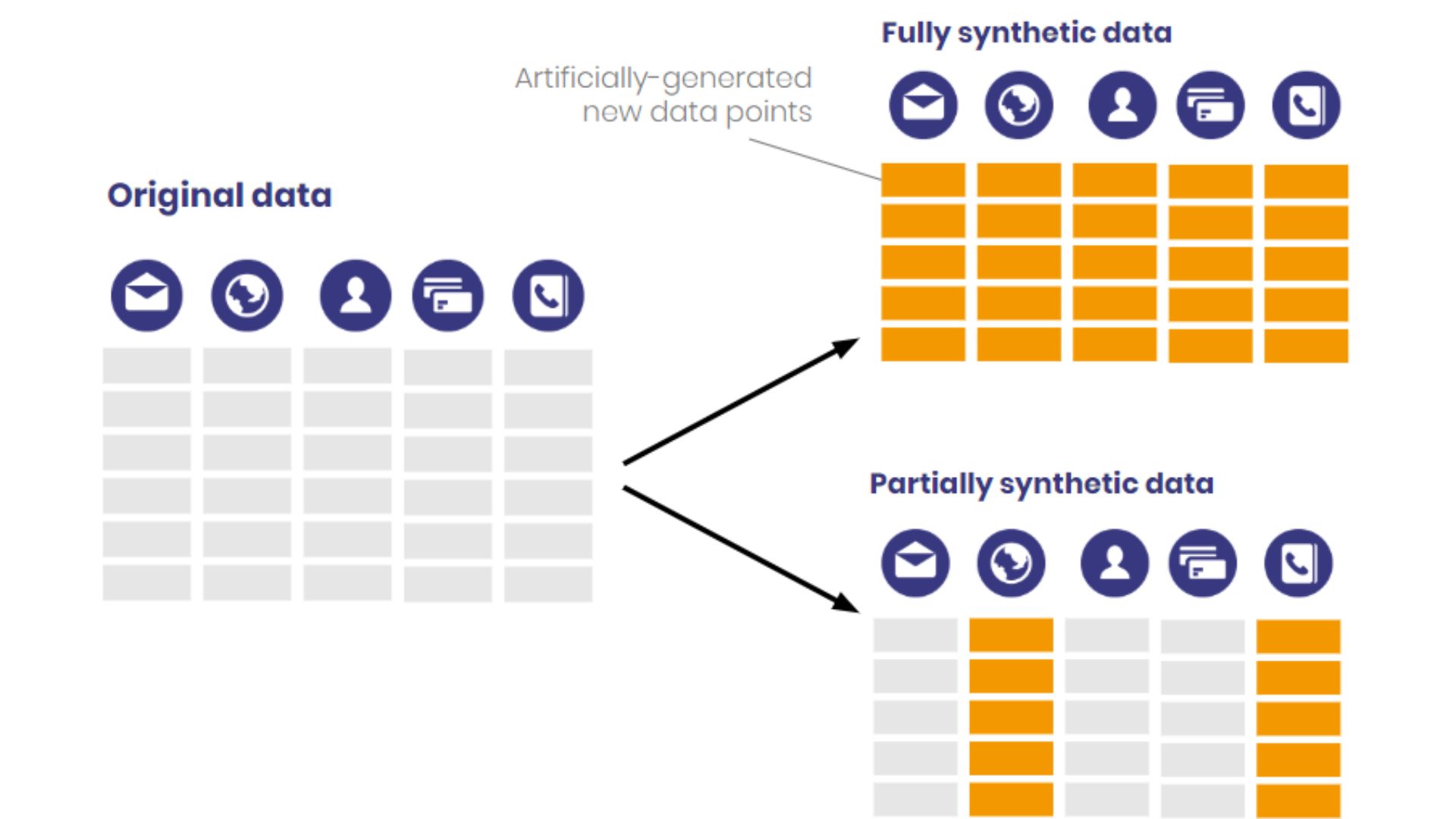
Knowing the type of synthetic data needed to solve a business challenge is crucial when choosing a method. Synthetic data is wholly or partially synthetic.
Fully Synthetic Data
Synthetic data is wholly produced and unrelated to real-world observations or datasets. This method creates data from scratch using algorithms and statistical approaches to simulate target domain patterns and characteristics. Data should be statistically similar to accurate data without observations.
Partially Synthetic Data
Hybrid partially synthetic data combines real-world observations with manufactured data. In this strategy, some dataset attributes are synthetically substituted or modified, while the rest are unchanged from real-world sources. The goal is to blend absolute data realism and synthetic data flexibility.
How To Generate Synthetic Data Step-by-step
The good news is that MOSTLY AI's synthetic data platform allows dataset synthesis without coding. Free access to the world's best synthetic data production, creating up to 100K rows every day, is even better. No credit card is needed, just a good subject table. First, create a free synthetic data-generating account with your email.
Upload Your Subject Table
Upload your subject table to MOSTLY AI's synthetic data platform. Click Jobs, then Launch a new job. Your subject table must be CSV or Parquet. Parquet files are advised.
Check Column Types
Check your subject table columns in the Table details tab after uploading. AI's synthetic data platform mostly finds supported column kinds. You should change them from what was automatically detected.
Train And Generate
Change the systemization method under Settings. You can choose how many data subjects the synthetic data generator should learn from and generate. Different use cases warrant changing them.
Check The Quality Of Your Synthetic Data
MOSTLY, AI's synthetic data platform generates interactive quality assurance reports for each collection. Check if the synthetic data set passed the accuracy and privacy criteria if you are new to synthetic data synthesis or less interested in generative AI data science. If each box has green check marks, your synthetic data can be shared, trained, or tested.
What Are Some Challenges Of Synthetic Data Generation?
Synthetic data has many benefits but also drawbacks.
Maintaining Quality
Quality is always a priority with training data, but synthetic data is made to improve model predictions. High-quality synthetic data matches the structure and statistical distributions of its source. Good synthetic data should look like actual data.
Avoiding Homogeneity
Model training requires variety and diversity since training data should mimic real-world data. If your model deciphers spending receipts in real life, some may be crumpled, have a coffee ring, or be taken in low light. Synthetic data creators must account for and create the same diversity of data the model could face in real life.
Approximating Randomness And Avoiding Erroneous Patterns
Humans and classical computers cannot generate randomness well. Over time, patterns may form that contradict the world's randomness. Thus, genuine randomness in synthetic data will be challenging to reproduce until quantum computing becomes more widespread. Conditional generative models can approximate randomness. Introducing the correct randomness for training is critical.
Frequently Asked Questions
Can Chatgpt Generate Synthetic Data?
No, ChatGPT does not generate synthetic data. It is a language model designed for natural language understanding and generation.
What Is An Example Of Synthetic Data?
Synthetic data examples include artificially generated datasets mimicking real-world characteristics, like creating fake customer records for testing purposes.
Is Synthetic Data The Future?
Yes, synthetic data is increasingly recognized as a crucial tool for overcoming data challenges, ensuring privacy, and driving innovation in machine learning and data science.
How To Create Synthetic Data In Excel?
In Excel, you can use functions like RAND() or RANDBETWEEN() to generate synthetic data or employ the "Data Analysis" tool for more advanced simulations and modeling.
Conclusion
Exploring synthetic data offers a transformative solution to challenges in obtaining and annotating large real-world datasets for machine learning. "Getting started with synthetic data" highlights its significance in revolutionizing AI applications, offering a cost-effective, scalable, and privacy-preserving alternative.
Understanding synthetic data's fundamentals is crucial, emphasizing its artificial nature and exempting it from data protection rules. The article guides non-coders through the practical steps using platforms like MOSTLY AI, emphasizing free access and simplicity.
Synthetic data's importance in enhancing privacy, overcoming scarcity, and providing cost-effective training alternatives is underscored, along with techniques like distribution-based methods and advanced technologies.